Teaching GPT-5 to Use a Computer
 Posted by Surya Dantuluri
Posted by Surya Dantuluri
Over the weekend, I won #3 at OpenAI's GPT-5 Hackathon with Archon - a copilot for your computer. It comes with a mini vision model for speed, and GPT-5 for variable reasoning to plan. I took some time to write about how it works, and our approach to building a self-driving computer with inference math, and the tradeoffs we made.
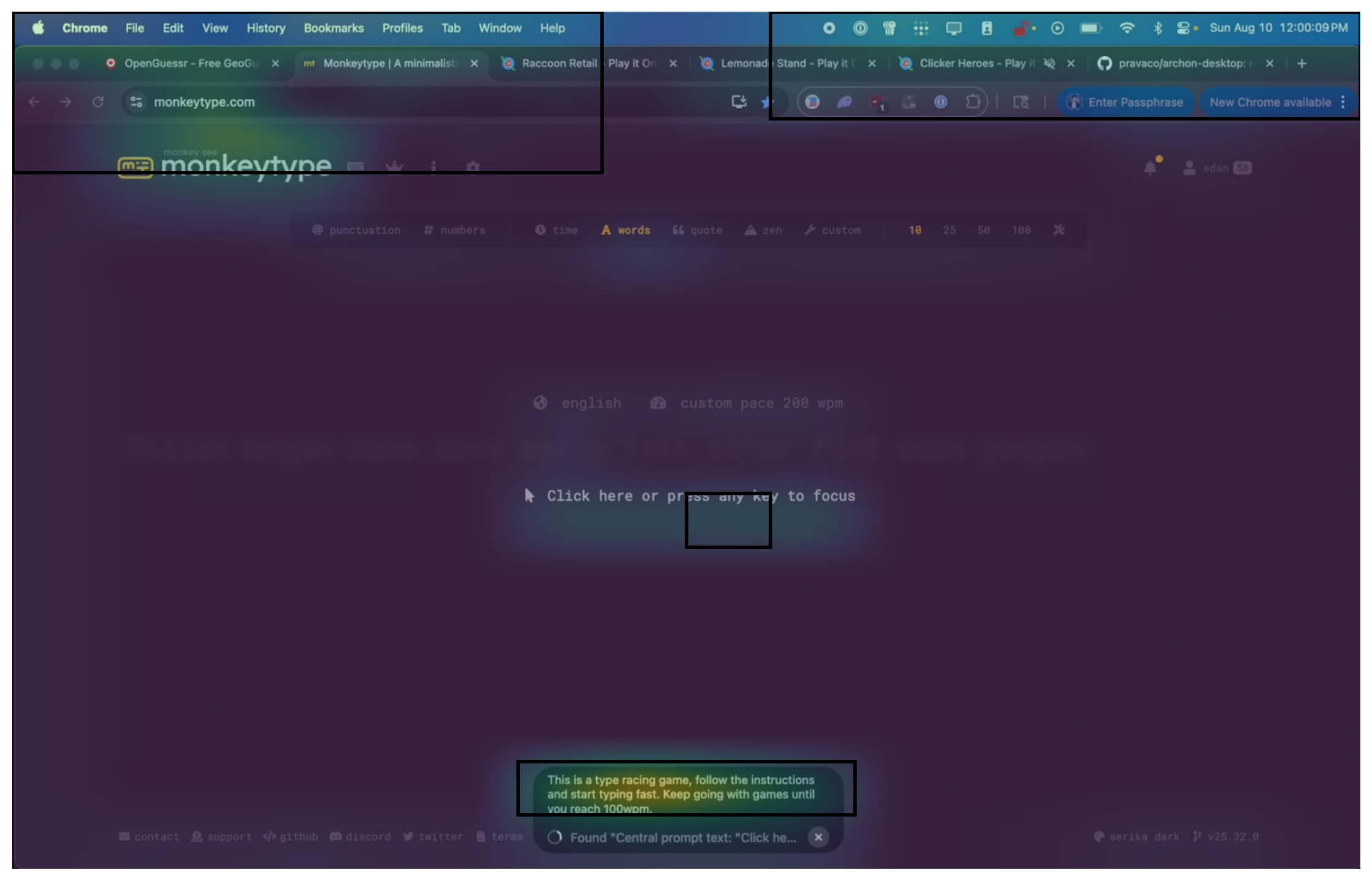
Archon is a small bar that sits at the bottom of your Mac/Windows screen where you can type what you want your computer to do in natural language. It takes screenshots to see what's on screen, uses GPT-5's reasoning to plan, then a custom fine-tuned model executes clicks and keystrokes. In a racing game demo with a single instruction to 'start playing' it recognized the view, used WASD, and navigated the track. Although it didn't win this time due to latency, its instruction-following ability was clearly superior to prior models. The goal is to make computers self-driving. Archon is a lightweight client demonstrating that GPT-5's powerful reasoning combined with tiny fine-tuned models can control any interface through natural language.
GPT-5: Why it worked for us
Archon was built entirely using GPT-5's advanced reasoning capabilities. We leveraged probably every aspect of GPT-5 from initial development to debugging to training. Codex CLI with GPT-5 with High Thinking enabled us to build the entire app, and GPT-5 with Vision enabled us to see and perceive the screen. GPT-5's reasoning ability was crucial for instruction following, and planning. This quite simply wasn't possible with any other model.
What makes GPT-5 particularly suited for computer control is its ability to reason through complex multi-step processes while maintaining context across long interactions. Unlike previous models that might hallucinate or lose track of the current state, GPT-5's chain-of-thought reasoning allows it to break down "start playing this game" into discrete, executable steps while adapting to unexpected UI changes.
We calibrated how much compute to use strategically to trade off accuracy and latency. For complex workflows, high reasoning effort mapped out interaction sequences with error handling. GPT-5-mini with function calling preambles enabled us to show the user what we were thinking while simultaneously calling our grounding model. This adaptive approach keeps the user in mind. Whether they need to go through complex, changing UIs, or just need to get something done, we can trade off reasoning for latency and vice versa.
How it actually works
Archon uses a hierarchical approach: a large reasoning model (GPT-5/o-series) decides what to do, and prava-fc-small (Prava's Fast Click grounding model) figures out exactly where to click. This split matters because reasoning and grounding are fundamentally different problems with different computational requirements.
The reasoning model sees the screen and your request, then outputs a semantic action: "click the blue Submit button at the bottom." Descriptions enable reasoning to be done in natural language. prava-fc-small takes that description plus the screenshot and outputs exact pixel coordinates: (523, 412). One model for the "what," another for the "where."
prava-fc-small (Prava's Fast Click grounding model) is a vision transformer (ViT) fine-tuned specifically for finding UI elements. It outputs exact (x, y) screen coordinates for clicking.
Why vision tokens are expensive (and how we optimize them)
For GPT-5's computer-using agent, each action involves vision, reasoning, and response. A 1920×1080 screenshot becomes 6 tiles at 170 tokens each, plus reasoning tokens billed as output.
Running the same workflow 100 times daily costs $940, over $28,000/month without caching. Each run takes 3–8 minutes, so what would take a human 50 minutes would take 5–13 hours of compute time. And because they're LLMs, they aren't deterministic everytime, compounding the cost and time.
Our approach: split reasoning from grounding. GPT-5 decides "click the blue Submit button," prava-fc-small finds the exact coordinates. We try to prevent re-encoding most patches by caching the patches themselves and reconstruct the difference in images overtime. Sometime this is inefficient in tasks that involve a lot of window switches however. Combined with a 3MB saliency scorer that identifies interactive regions, we achieve 70%+ cache hits and 10–50ms grounding latency.
Instead of throwing away dead space, we also just downsample irrelevant regions, keeping the important UI elements at full resolution.
GRPO
We trained prava-fc-small with GRPO (Group Relative Policy Optimization), where rewards are binary: 1 if the click lands inside the target UI element, 0 otherwise. Patches work well for this because they're small enough that clicking anywhere within a patch-covered element still gets rewarded.
To scale training data, we used trajectory augmentation on human demonstrations. From one recorded workflow, we generate multiple related trajectories by varying timing, UI states, and interaction patterns - effectively "boosting" the grounding model's robustness across different scenarios.
While testing, prava-fc-small was really bad at clicking bright red buttons, compared to tiny blue buttons it was clicking. We suspect this is because the bright red buttons are more likely to be at the center of the element, and the tiny blue buttons are more likely to be at the edge of the element. More work is needed to make the model more robust and for us to interpret all its capabilities.
Speed: adaptive compute that feels instant
Test-time compute is getting extremely hyped these days, particularly off of the success of the o-series models. In my experience, I personally get much usage from GPT-5 Pro and previously o3-pro. The reason is because a lot of my day-to-day work revolves around "knowledge work". Good thing for prava-fc-small is that it's a lot of "grounding work" and not a lot of "knowledge work". You can get a lot of mileage out of a 7B model if you instead vary the reasoning and determine how to properly pipeline the tasks.
On this path, prava-fc-small runs alone (no planner call), hitting ~50 ms per action on a A100. The router only escalates when signals are uncertain: high saliency entropy, too many candidate targets, recent misclicks, or ambiguous copy (e.g., multiple "Submit" buttons). When that trips, we pipeline one step ahead: Step N (simple) executes now while the reasoner prepares a short plan for Step N+1. The router is a simple policy that looks at the signals and decides whether to escalate or not.
The fundamental tradeoff is simple: consumers want one thing done fast, enterprises want many things done efficiently. Same model, different routing strategy.
For the typical consumer, we think it's better to bias toward the fast path (planner stays cold unless ambiguity is detected). In enterprise, we enable continuous batching for planner calls, short aggregation windows, and aggressive prefix caching; prava-fc-small stays on-GPU so grounding still feels immediate.
After ~1 hour of use we typically see a pretty high patch-cache hit‑rate where similar patches (imagine a screenshot of a button) are cached and reused. Verifying is cheap (single screenshot + state predicate), so we keep iterating quickly without silent drift.
The encompassing effect is that compared to computer-use models today, many steps can finish in < 100 ms end-to-end; a 20‑step flow can land in a few seconds without the "stop‑and‑think" feel.
What's next: streaming control and unifying the stack
In the future we hope to run a streaming capture pipeline similar to Gemma 3. Consuming frames at 20-30 fps, emitting actions at 5-10 Hz, and verifying state on each commit. This closes the perception-action loop for drag/hover/scroll and makes motion feel natural. The planner hooks into the same stream, but only for escalations.
We also plan to compile solved steps into micro-policies. If you're running something like a RPA task or similar workflow as before, you can simply run the execution locally (with prava-fc-small running locally) and not have to worry about the planning. Over time, the planner is a background teacher, not a crutch. We also found that recording screens on computers is a great way to get enough data to do RL training which materially boosts the performance of the model for each specific use case(s) in each vertical/profession.
We will distill those plans into the local model so more steps stay on the fast path. The path forward is to adopt an end-to-end approach to the problem. For Tesla that's camera, steering, acceleration. For us it's screen, mouse, keyboard.
Eventually we'll get rid of all the brittle policies and controls and have a model that can think on a second-order to understand how much compute it requires to do a task. Today we want to keep a planner in the loop for rare edge cases and safety; as the executor absorbs those patterns (via streaming, macros, distillation), the system becomes simpler and end-to-end.


Related Work
He, Y., Jin, J., & Liu, P. (2025). Efficient Agent Training for Computer Use. arXiv preprint arXiv:2505.13909.
Yang, Y., Li, D., Dai, Y., Yang, Y., Luo, Z., Zhao, Z., Hu, Z., Huang, J., Saha, A., Chen, Z., Xu, R., Pan, L., Xiong, C., & Li, J. (2025). GTA1: GUI Test-time Scaling Agent. arXiv preprint arXiv:2507.05791.