Can You Infinitely Learn with Online RL?
 Posted by Surya Dantuluri
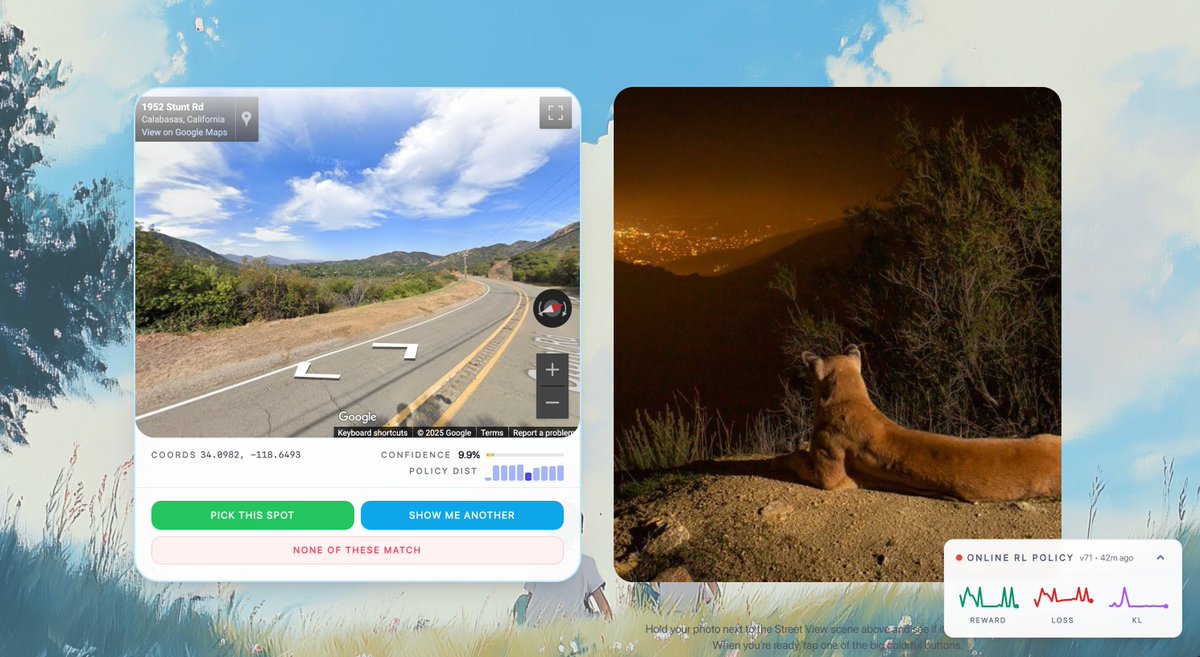
Posted by Surya DantuluriLast week I made Geospot Infinity, a photo-to-GPS model. For each upload, we retrieved 10 candidate coordinates and ranked them for the user. Users then pick the closest. We attempted to learn from every interaction via online RL. In reality over 65% of users clicked the first guess regardless of accuracy, effectively nullifying our ability to learn anything. In fact the online RL policy degraded output estimates by 414km or 17% worse than baseline.
Metric Results
| Metric | Error (km) | vs Baseline |
|---|---|---|
| Baseline (GeoCLIP top-1) | 2,464 | — |
| Baseline@10 (best-of-10) | 1,276 | −48% ✓ |
| Our Policy (REINFORCE) | 2,878 | +17% ✗ |
I froze GeoCLIP which is a ViT-L/14 vision encoder + small image MLP + location encoder that pairs images to 10 candidate coordinates. I put a tiny 3-layer MLP head that re-scores those 10 candidates:
# Input: [z_img(512), z_loc(512), similarity(1), base_prob(1)] → 1026-d
ranker = nn.Sequential(
nn.Linear(1026, 256), nn.ReLU(),
nn.Linear(256, 256), nn.ReLU(),
nn.Linear(256, 1)
)Effectively a re-ranker to see if it could learn geoguessing better than the backbone. My intention was to build an online RL policy in <12 hours which this simple architecture satisfied. The policy head samples rankings via Plackett-Luce (a probabilistic model for ranking permutations) and optimizes a REINFORCE objective with KL regularization:
where R = reward from user click position, b = EMA baseline, β = KL penalty against a Polyak-averaged behavior policy (a slowly-updated copy of the policy that prevents the model from changing too quickly between updates).
Throughout the next few days KL stayed under 0.01 meaning we weren't learning much, and rewards were high because users clicked the first option. The shape of those rewards correlated with position so if there was no "good" prediction similar to the uploaded photo, reward would be negative. In short, the interface optimized itself for preference tuning, not geodesic accuracy.
Designing for the right ceiling
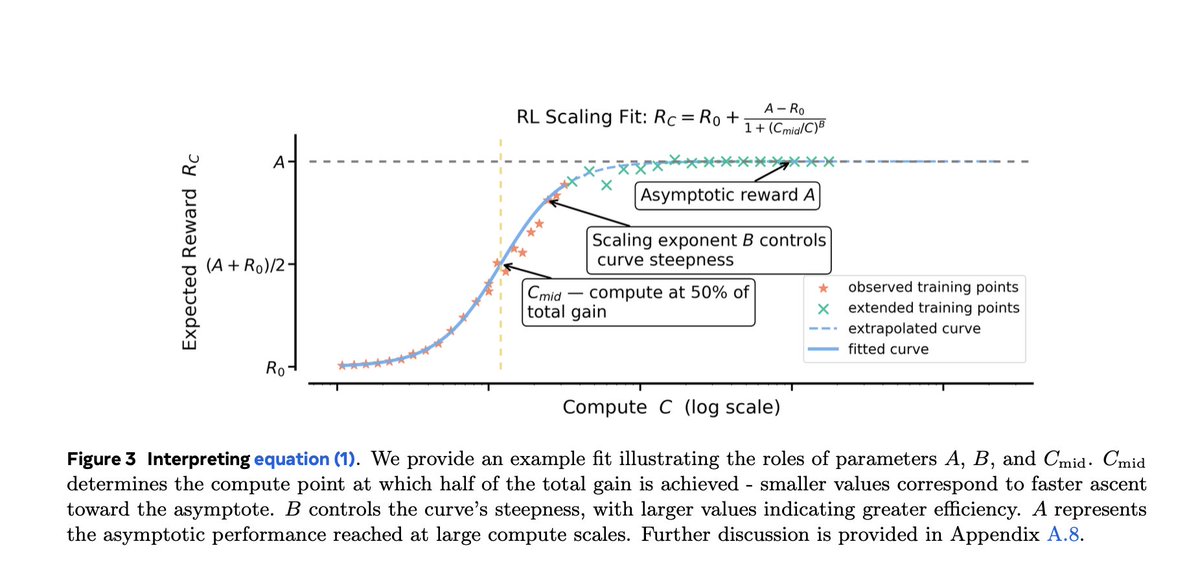
On October 15th, Meta published a paper about scaling RL for LLMs, conceptually similar to the Chinchilla scaling laws paper and I recommend reading it. In the abstract it showed LLM RL scaling follows a sigmoid:
A = ceiling (asymptote) B = efficiency C = compute
To lift the A you want:
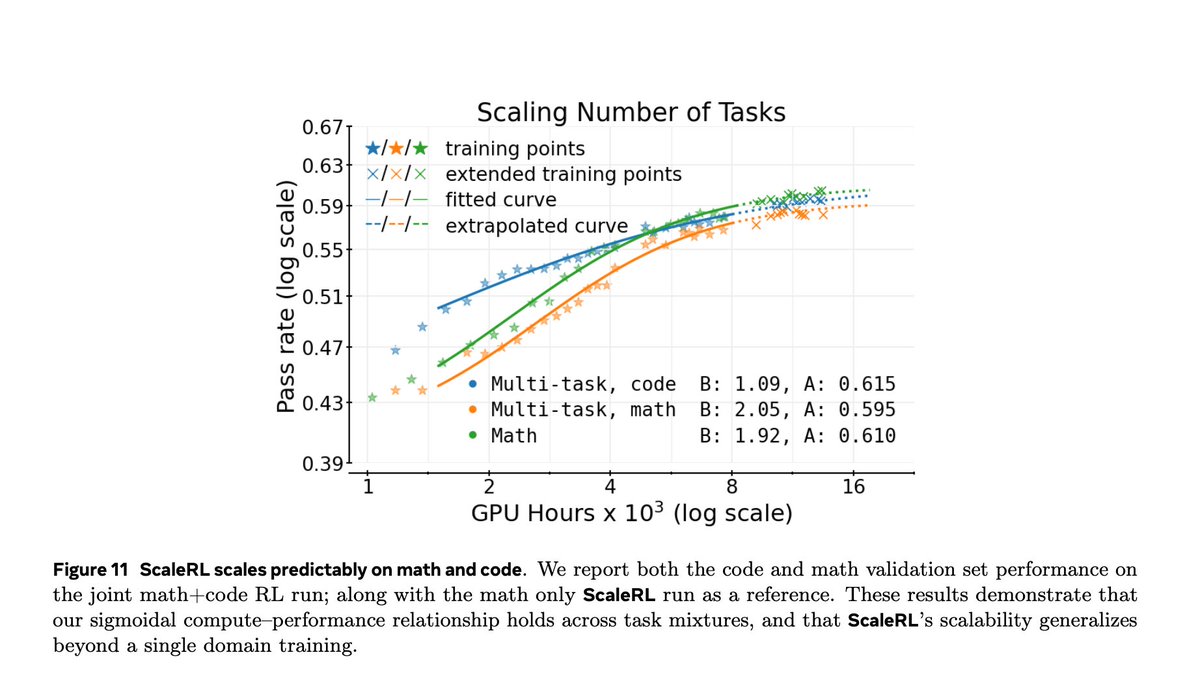
- Bigger models: 8 B → 17 B×16 MoE lifts A from 0.610 → 0.710
- More context: 14 k → 32 k tokens = 0.610 → 0.645
- Larger batches: 512 → 2048 = 0.605 → 0.645
- Better precision: FP32 logits + CISPO loss = 0.52 → 0.61
Implicating that RL (in this context we assume online/offline is how you sample from distribution) is a capacity, context, and for us a reward/data framing issue. Structured/dense verifiers like math and coding are axes to push RL ceilings because we can verify them cheaply extremely quickly. The next step is how do we apply this in economically valuable domains? What if we rolled up the US economy and turned it into a huge verifiable engine where the reward is USD and the rollout is you being assigned a job to do? You can't grind the ceiling(A) but you can raise it. And ultimately your distribution also defines the ceiling.
Learning to reward the reward
Yesterday I refactored Geospot Infinity to use DPO since the previous REINFORCE setup was implicitly preference tuning. Each click generates pairs comparing winner yw vs losers yl, optimizing:
where yw = clicked candidate, yl = lower-ranked candidates, rθ = trainable policy logits, rref = frozen reference baseline, and β = KL constraint strength. The trainable policy improves via gradient descent against the frozen reference. Try it: geospot.sdan.io. I also made the DPO code available here.
If the top 100 on Geoguessr dot com only used my model, the online RL policy would be great forever. Similarly if the top coders used Cursor Tab completion then it would get better, but behaviorally what happens if these users keep accepting everything, what happens? Seems like learning how to reward the reward is the implicit challenge. You want a never ending rotation of... smart users.
You can't optimize past your distribution 💫 but you can change it 💫